Dağılım grafiği
Dağılım grafiği, veri kümesindeki her değerin bir nokta ile temsil edildiği bir diyagramdır.
Matplotlib modülünün dağılım grafikleri çizmek için bir yöntemi vardır, biri x ekseninin değerleri için ve diğeri y ekseninin değerleri için aynı uzunlukta iki diziye ihtiyaç duyar:
x = [5,7,8,7,2,17,2,9,4,11,12,9,6]
y = [99,86,87,88,111,86,103,87,94,78,77,85,86]
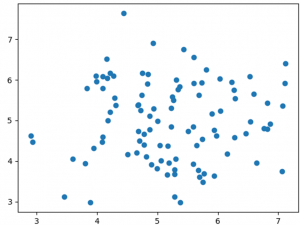
X dizisi her arabanın yaşını temsil eder.
Y dizisi her arabanın hızını temsil eder.
Örnek :
Bir dağılım grafiği diyagramı çizmek için scatter () yöntemini kullanalım:
import matplotlib.pyplot as plt
x = [5,7,8,7,2,17,2,9,4,11,12,9,6]
y = [99,86,87,88,111,86,103,87,94,78,77,85,86]
plt.scatter(x, y)
plt.show()
Sonuç :
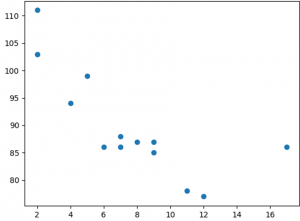
Dağılım Grafiği Açıklaması
X ekseni yaşları ve y ekseni hızları temsil eder. Diyagramdan okuyabileceğimiz şey, en hızlı iki arabanın 2 yaşında ve en yavaş arabanın 12 yaşında olmasıdır.
Not: Görünüşe göre araba ne kadar yeni olursa o kadar hızlı olur, ancak bu sadece bir tesadüf olabilir, sonuçta sadece 13 araba kaydettik.
Rasgele Veri Dağılımları
Makine Öğrenimi’nde veri kümeleri binlerce, hatta milyonlarca değer içerebilir.
Bir algoritmayı test ederken gerçek dünya verileriniz olmayabilir, rastgele oluşturulmuş değerleri kullanmanız gerekebilir.
Önceki bölümde öğrendiğimiz gibi, NumPy modülü bize bu konuda yardımcı olabilir!
Her ikisi de normal veri dağılımından 1000 rasgele sayı ile dolu iki dizi oluşturalım.
İlk dizi, 1.0 standart sapma ve 5.0 ortalamaya ayarlanmış olacaktır.
İkinci dizi, 2.0 standart sapma ve 10.0 ortalamaya ayarlanmış olacaktır:
Örnek :
1000 noktalı bir dağılım grafiği:
import numpyimport matplotlib.pyplot as pltx = numpy.random.normal(5.0, 1.0, 1000)y = numpy.random.normal(10.0, 2.0, 1000)plt.scatter(x, y)plt.show()Sonuç :
 Dağılım Grafiği Açıklaması
Noktaların x ekseni üzerindeki 5 ve y ekseni üzerindeki 10 değerinin etrafında yoğunlaştığını görebiliriz.
Ayrıca, aralığın y ekseninde x ekseninden daha geniş olduğunu görebiliriz.
-Burak Can Görgülü
Dağılım Grafiği Açıklaması
Noktaların x ekseni üzerindeki 5 ve y ekseni üzerindeki 10 değerinin etrafında yoğunlaştığını görebiliriz.
Ayrıca, aralığın y ekseninde x ekseninden daha geniş olduğunu görebiliriz.
-Burak Can Görgülü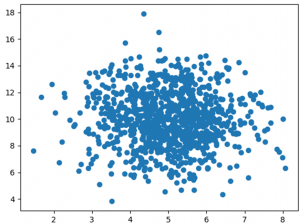 Dağılım Grafiği Açıklaması
Dağılım Grafiği Açıklaması
{kind=link}